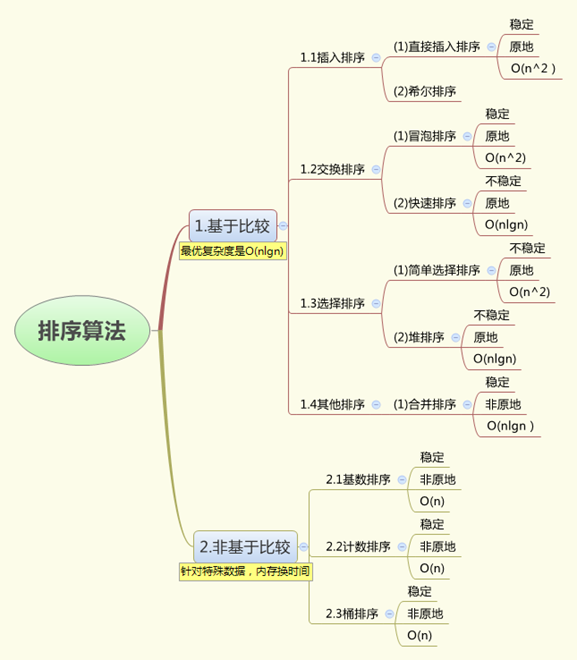
本文梳理算法均需结合数据预处理(缺失值处理、标准化)与评估指标(准确率/F1值)使用[[6]9。实际应用中,需根据数据规模与问题复杂度选择分布式框架(如Spark MLlib)提升效率6。
“从关联规则到深度学习,算法是业务增长的隐形引擎。建议新人先掌握决策树/回归,再攻神经网络!”
“聚类像给数据写诗,K-Means把用户分成‘晨曦’‘夜猫’群组,营销转化率翻倍!🌙”
🔍 常用数据分析算法全景解析
数据分析的核心在于通过算法挖掘数据价值,以下结合应用场景与原理,梳理主流算法体系:
🧩 一、分类算法:预测离散标签
- 逻辑回归
- 原理:基于sigmoid函数将线性回归结果映射为概率(0-1),解决二分类问题。
- 场景:金融风控(预测用户违约概率)、广告点击率预估[[1]9。
- 优势:模型可解释性强,易于部署。
- 决策树与随机森林
- 原理:通过特征分裂构建树形规则(ID3/C4.5/CART算法);随机森林集成多棵树降低过拟合。
- 场景:客户分群(如活跃用户/沉默用户识别)、医疗诊断[[1][6]9。
- 创新点:XGBoost引入正则化与梯度提升,精度更高9。
- 朴素贝叶斯
- 原理:基于贝叶斯定理与特征条件独立假设,计算后验概率。
- 场景:垃圾邮件过滤、新闻文本分类(NLP领域)[[1]9。
📈 二、回归算法:预测连续值
- 线性回归
- 原理:拟合自变量与因变量的线性关系(最小二乘法优化)。
- 场景:房价预测、销售额趋势分析[[3]6。
- 支持向量机(SVM)
- 原理:寻找最大化分类间隔的超平面,可处理非线性问题(核函数)。
- 场景:股票波动预测、图像识别[[1]9。
🌐 三、聚类算法:无监督数据分群
- K-Means
- 原理:迭代将数据划分为K个簇,最小化簇内距离。
- 场景:用户画像构建(如电商客户细分)、异常检测[[6]11。
- 层次聚类(Hierarchy)
- 原理:逐层合并或分裂簇,形成树状结构。
- 场景:基因序列分析、社交网络社区发现6。
🔗 四、关联分析与时序预测
- Apriori与FP-Growth
- 原理:挖掘频繁项集(如{啤酒→尿布}购物篮规则)。
- 场景:推荐系统(协同过滤)、交叉销售策略[[6]10。
- ARIMA时间序列
- 原理:结合自回归(AR)、差分(I)、移动平均(MA)预测未来值。
- 场景:电力负荷预测、销量季节性分析6。
⚙️ 五、特征工程与深度学习
- 特征处理:主成分分析(PCA)降维、WOE编码优化特征表达6。
- 深度学习:
- LSTM:处理长序列依赖(如股价预测)6。
- 卷积神经网络(CNN):图像识别、视频分析2。
💬 网友热评:
- @数据探险家
:
“逻辑回归+特征交叉简直是金融风控的神器!试过XGBoost后模型AUC直接涨了5个点~ ✨”

相关问答
- 常用的9种数据分析方法,建议收藏
- 答:常用的9种数据分析方法包括:逻辑树分析法:用于拆解复杂问题
,将抽象概念量化,适用于多种场景,如求职面试中的估算问题和日常生活中的收益考量。多维度拆解分析法:类似多功能尺,将模糊问题分解为清晰的子问题,帮助从不同角度全面了解事物。PEST分析法:行业分析的重要工具,关注政治、经济、社会和技术四...
- 多模态数据分析系统
- 企业回答:Play Video 七鑫易维是致力于机器视觉和人工智能领域的高新科技企业,迄今已专注眼球追踪技术的研发、创新与应用超过14年,拥有完全自主知识产权,全球专利总量500余项。 作为眼球追踪技术领域的全球知名品牌,七鑫易维的产品体系覆盖眼动分析、...
- 大数据常用哪些算法?
- 答:大数据算法有多种,以下是一些主要的算法:一、聚类算法 聚类算法是一种无监督学习的算法,它将相似的数据点划分到同一个集群中。常见的聚类算法包括K均值聚类、层次聚类等。这些算法在处理大数据时能够有效地进行数据分组,帮助发现数据中的模式和结构。二、分类算法 分类算法是一种监督学习的算法,它通过...
文章来源: 用户投稿版权声明:除非特别标注,否则均为本站原创文章,转载时请以链接形式注明文章出处。





